
Given the head of a linked list, return the node where the cycle begins. If there is no cycle, return null.
Here’s the [Problem Link] to begin with.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail’s next pointer is connected to (0-indexed). It is -1 if there is no cycle. Note that pos is not passed as a parameter.
Do not modify the linked list.
Example 1:

Input: head = [3,2,0,-4], pos = 1
Output: tail connects to node index 1
Explanation: There is a cycle in the linked list, where tail connects to the second node.
Example 2:
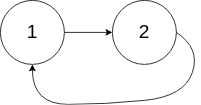
Input: head = [1,2], pos = 0
Output: tail connects to node index 0
Explanation: There is a cycle in the linked list, where tail connects to the first node.
Example 3:

Input: head = [1], pos = -1
Output: no cycle
Explanation: There is no cycle in the linked list.
Constraints:
- The number of the nodes in the list is in the range
[0, 104]. -105 <= Node.val <= 105posis-1or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
Solution 1: Brute Force Approach (Using Set)
Intuition
This is similar to the previous cycle detection problem, but instead of just checking if there’s a cycle, we need to find exactly where the cycle starts. Think of it like walking through a maze while dropping breadcrumbs. The moment you find a breadcrumb you’ve already dropped, that’s exactly where you started going in circles!
Detailed Approach
- Create a Tracking System: Use a set to remember all the nodes we’ve visited
- Walk Through the List: Move through each node one by one
- Check Before Adding: At each node, check if we’ve seen it before
- Found the Cycle Start: If we find a node we’ve already visited, that’s where the cycle begins
- Reached the End: If we reach the end (None), there’s no cycle
Code
class Solution:
def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:
my_set = set() # Set to store visited nodes
temp = head # Current node we're examining
while temp is not None:
if temp in my_set: # Check if we've seen this node before
return temp # This is where the cycle starts!
my_set.add(temp) # Remember this node for future
temp = temp.next # Move to the next node
return None # Reached end, no cycle foundCode Explanation
We start from the head and visit each node one by one. Before moving to the next node, we check if the current node is already in our set. If it is, we’ve found the exact node where the cycle begins because this is the first time we’re visiting a node for the second time. If it’s not in the set, we add it and continue. If we reach the end of the list (temp becomes None), it means there’s no cycle.
Dry Run
Let’s trace through a list with cycle: 1 -> 2 -> 3 -> 4 -> 2 (4 points back to 2)
Step 1: temp=1, my_set={}, add 1: my_set={1}
Step 2: temp=2, my_set={1}, add 2: my_set={1, 2}
Step 3: temp=3, my_set={1, 2}, add 3: my_set={1, 2, 3}
Step 4: temp=4, my_set={1, 2, 3}, add 4: my_set={1, 2, 3, 4}
Step 5: temp=2, my_set={1, 2, 3, 4}, 2 is already in set → return node 2
Result: Cycle starts at node 2!
Time and Space Complexity
- Time Complexity: O(n) – We visit each node at most once before detecting the cycle start
- Space Complexity: O(n) – In worst case, we store all nodes in the set
Simplifying It
This approach is straightforward – keep a record of everywhere you’ve been, and the first place you visit twice is where the cycle begins. However, it uses extra memory to store all the visited nodes.
Solution 2: Optimal Approach (Floyd’s Algorithm + Cycle Start Detection)
Intuition
This is like a two-phase detective story! First, we use the “tortoise and hare” method to confirm there’s a cycle. Then, we use a clever mathematical trick: when the two pointers meet inside the cycle, we reset one pointer to the head and move both pointers one step at a time. They will meet exactly at the cycle’s starting point!
Detailed Approach
- Phase 1 – Detect Cycle: Use two pointers (slow and fast) to detect if a cycle exists
- Phase 2 – Find Cycle Start: Once cycle is detected, reset slow pointer to head
- Move Both Pointers: Move both pointers one step at a time until they meet
- Meeting Point: The point where they meet is the start of the cycle
Code
class Solution:
def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:
slow = head # Slow pointer (tortoise)
fast = head # Fast pointer (hare)
# Phase 1: Detect if cycle exists
while fast and fast.next:
slow = slow.next # Move slow pointer 1 step
fast = fast.next.next # Move fast pointer 2 steps
if slow == fast: # Cycle detected!
# Phase 2: Find cycle start
slow = head # Reset slow to head
while slow != fast:
slow = slow.next # Move both pointers 1 step each
fast = fast.next
return slow # They meet at cycle start
return None # No cycle foundCode Explanation
This solution works in two phases. In Phase 1, we use the classic two-pointer technique to detect if a cycle exists. Once we confirm there’s a cycle (when slow equals fast), we enter Phase 2. We reset the slow pointer to the head and then move both pointers one step at a time. Due to the mathematical properties of the cycle, they will meet exactly at the node where the cycle begins.
Dry Run
Let’s trace through: 1 -> 2 -> 3 -> 4 -> 2 (4 points back to 2)
Phase 1 – Cycle Detection:
- Initial: slow=1, fast=1
- Step 1: slow=2, fast=3
- Step 2: slow=3, fast=2 (cycle)
- Step 3: slow=4, fast=4
- Cycle detected! slow == fast at node 4
Phase 2 – Find Cycle Start:
- Reset slow to head: slow=1, fast=4
- Step 1: slow=2, fast=2
- They meet at node 2!
Result: Cycle starts at node 2
Time and Space Complexity
- Time Complexity: O(n) – We traverse the list at most twice
- Space Complexity: O(1) – We only use two pointer variables
Simplifying It
The magic here is in the math! When the two pointers meet during cycle detection, the distance from the head to the cycle start equals the distance from the meeting point to the cycle start (when moving forward in the cycle). This is why resetting one pointer to head and moving both at the same speed makes them meet at the cycle start.
Why Does the Optimal Solution Work?
Let’s break down the math in simple terms:
- L1 = Distance from head to cycle start
- L2 = Distance from cycle start to meeting point
- C = Cycle length
When fast and slow meet:
- Slow traveled: L1 + L2
- Fast traveled: L1 + L2 + C (one extra cycle)
- Since fast moves twice as fast: 2(L1 + L2) = L1 + L2 + C
- Simplifying: L1 + L2 = C, so L1 = C – L2
This means the distance from head to cycle start (L1) equals the distance from meeting point to cycle start (C – L2). That’s why they meet at the cycle start!
Summary
| Approach | Time | Space | Difficulty | Best For |
|---|---|---|---|---|
| Brute Force (Set) | O(n) | O(n) | Easy | Learning the concept |
| Two Pointers (Floyd’s) | O(n) | O(1) | Hard | Production code |
The two pointers approach is generally preferred because it uses constant space while maintaining the same time efficiency. However, the brute force approach is more intuitive and easier to understand when you’re first learning about cycle detection.
The optimal solution is a beautiful example of how mathematical insights can lead to elegant algorithms. While it’s trickier to understand initially, mastering this technique will help you solve many advanced linked list problems!
For any changes to the article, kindly email at code@codeanddebug.in or contact us at +91-9712928220.